A Synergistic Future: Integrating AI and Human Expertise for Robust Cell Annotation
The world of single-cell genomics is buzzing with excitement, and for good reason. A new wave of powerful AI tools, including foundation models like Geneformer and scGPT, promises to automate one of the most laborious steps in scRNA-seq analysis: cell type annotation. What once took experts weeks of painstaking manual work can now be done in minutes, assigning identities to millions of cells with the click of a button. This acceleration is revolutionary, opening the door to system-level insights at an unprecedented scale.
As we integrate these powerful tools into our workflows, it's important to recognize their role as a part of a larger analytical process. While they often report impressive accuracy scores, these aggregate metrics can sometimes mask important nuances in the data. High overall accuracy can be driven by the model's ability to correctly label abundant, well-defined cell types, while potentially being less certain about rare, novel, or transitional cell states that often hold the key to biological discovery. This highlights the need for a collaborative approach where the power of automation is paired with human expertise.
The Challenge of Data Integrity in an Era of Big Data
The effectiveness of any data-driven model is intrinsically linked to the quality of the data it learns from. This is a well-understood principle in computational biology. Today's advanced models are trained on massive public data repositories like the Chan Zuckerberg CELLxGENE platform and the Human Cell Atlas, which together contain information from hundreds of millions of cells. These incredible resources are the bedrock of modern single-cell research.
This scale presents both an opportunity and a challenge. It is the reason these models are so powerful, but it also means we must be diligent about the quality of the annotations we contribute back to the community. An inadvertent mislabeling in one study, if uploaded to a public archive, can become part of the "ground truth" for the next wave of research. This creates the potential for a "data cascade," a known phenomenon in bioinformatics where an initial error can be propagated through the ecosystem as it is used in subsequent analyses and model training cycles. Ensuring the integrity of our shared data resources is a collective responsibility that benefits the entire field.
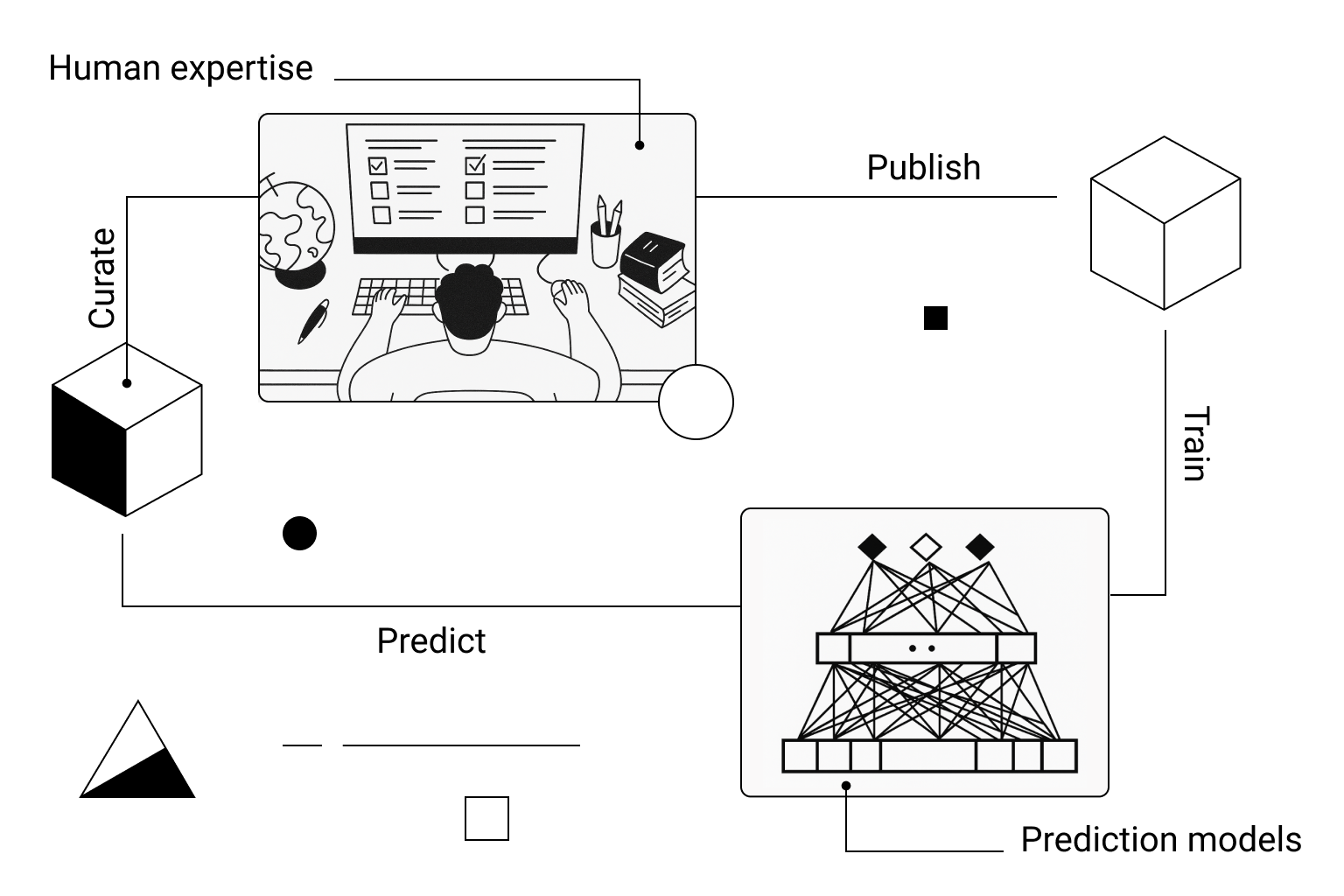
The Human-in-the-Loop: A Model for Deeper Insight
The most effective path forward is not a choice between automation and manual curation, but a synthesis of the two. We should view advanced computational tools as powerful hypothesis-generation engines - brilliant assistants that can produce a highly accurate first draft of the cellular landscape in a fraction of the time it would take a human. This frees up the human expert to focus on the higher-level cognitive tasks of validation, interpretation, and discovery.
A robust analysis workflow should therefore embrace a human-in-the-loop model, where expert verification is a standard and crucial step. This process typically involves:
1. Generating an Initial Hypothesis: Use an automated tool to generate a preliminary set of cell labels.
2. Verifying with Known Markers: For each proposed label, scrutinize the data. Use visualization tools like dot plots and feature plots to confirm the expression of canonical marker genes from established databases like CellMarker and PanglaoDB. Does the cluster labeled "T-cells" actually express CD3D? Is it negative for B-cell markers like MS4A1?
3. Applying Biological Context: Step back and ask if the results are biologically plausible. Is this cell type expected in this tissue and condition? This is where deep domain knowledge is irreplaceable.
4. Iterating and Refining: Correct any mislabeled clusters. For heterogeneous groups, consider sub-clustering to reveal finer subtypes that automated methods may have missed. Documenting the rationale for every decision is key to ensuring the analysis is transparent and reproducible.
A Call for Collaborative Best Practices
As we navigate this new era, ensuring the quality and reliability of our findings is a shared responsibility.
- For researchers, the goal is to build a practice of "trust, but verify." The speed of automation is a powerful asset, but it is most valuable when combined with the rigor of expert validation.
- For tool developers, the focus is increasingly on creating more transparent and collaborative systems. This means not only providing robust algorithms but also facilitating the human verification process. Features that allow users to easily review, correct, and annotate cell types can significantly enhance the reliability of the predictions.
- For the community, we can work toward better standards for tracking annotation provenance in our public databases, making it clear how a label was derived and increasing the reliability of our shared resources.
Conclusion
The integration of advanced computational methods in genomics, particularly in Automated Cell Type Annotation, opens up extraordinary possibilities. These tools empower us to ask and answer questions at an unprecedented scale and speed. However, as we embrace these exciting advancements, it is essential to pair computational power with human insight and critical evaluation. Technology alone cannot guarantee accuracy; human verification remains a crucial step in ensuring the reliability of our annotations
By doing so, we move beyond merely accelerating analysis - we lay the foundation for more robust, trustworthy models and a deeper understanding of cellular biology. As we continue to explore this rapidly evolving field, let us remember that while technology is a powerful ally, it is our responsibility to use it wisely and validate our discoveries with care.